さくらVPSのCentOS6をMondRescueでリストアしてみた。
無料お試しのVPS2Gを借りて、デフォルトインストールされている
CentOS6をバックアップしてisoをダウンロードしてから、
同じサーバに対してisoイメージインストールでリストアを実験してみた。
一応再度インストール方法から。
今回の対象はCentOS release 6.7です。
# wget ftp://ftp.mondorescue.org//rhel/6/x86_64/mondorescue.repo
# mv mondorescue.repo /etc/yum.repos.d/
# yum -y install dvd+rw-tools
# yum install --enablerepo=mondorescue mondo
# yum install lzop
# cd /
# mkdir backup
# mondoarchive -Oi -L -N -s 4480m -d /backup -E /backup -p sakura-`hostname`-`date +%Y-%m-%d`
出来たisoファイルをダウンロードしておく。
その後、さくらVPSの管理画面にログインして「OSインストール」から「ISOイメージインストール」を選択する。
「SFTP」のアカウントを作成するボタンがあるのでクリックしてISOイメージアップロード先の情報を取得する。
SFTPで接続して「iso」フォルダに先ほどダウンロードしておいたisoイメージファイルをアップロードする。
アップロード終了後に再度「OSインストール」から「ISOイメージインストール」に進むと、
アップロードしたisoファイルが表示されているはずなので内容を確認してさらに「VirtIOを有効にする」の
チェックを外してから「設定内容を確認する」をクリック。
確認画面が出るので「インストールを実行する」をクリックしてリストアを開始する。
※「VirtIOを有効にする」にチェックが入っていた状態だと「expert」モードの時に「fdisk -l」しても
デバイスが無いも表示されなかったので、チェックを外した。
Mondo Rescueの画面になるので「expert」を入力する。
boot: expert
sh-4.1# fdisk -l
/dev/sdaとかが表示されているはず。
sh-4.1# vi /tmp/mountlist.txt
ファイル内の「vda」の箇所をすべて「sda」に変更する。
sh-4.1# mondorestore
「Automatically」を選択
リストアが始まる。
たぶんこの時に画面の下に
Formatting /dev/sda3 as ext4...OK
Formatting /dev/sda1 as ext4...OK
Formatting /dev/sda2 as swap...OK
All partitions were mounted OK.
が出れば順調に進んでいるはず。
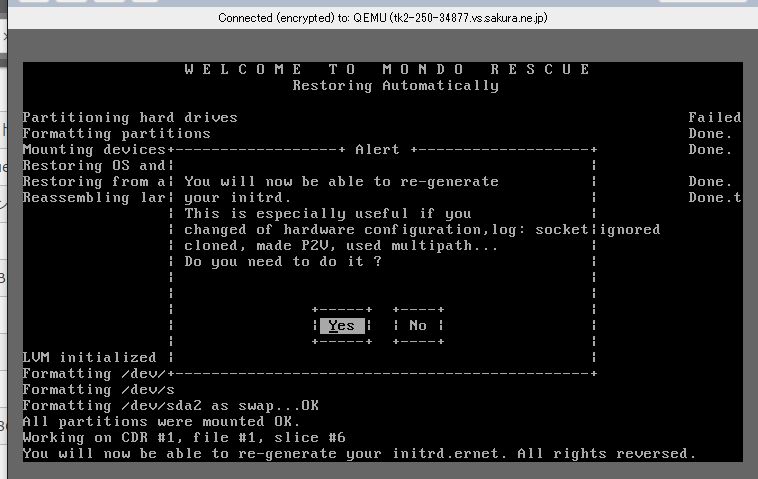
次に
You will now be able to re-generate your initrd.
This is especially useful if you changed of hardware configuration,log: socket ignored cloned, made P2V, used multipath…
Do you need to do it ?
と出るので「Yes」を選択。
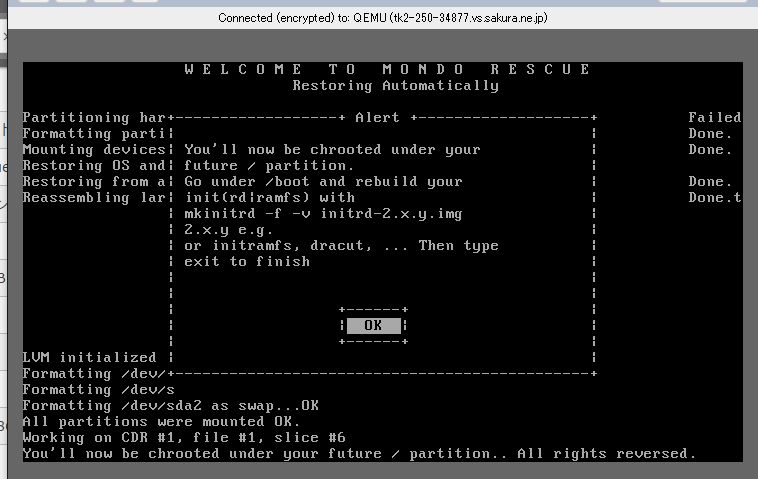
次に
You’ll now be chrooted under your future / partition.
Go under /boot and rebuild your init(rd|ramfs) with
mkinitrd -f -v initrd-2.x.y.img 2.x.y
e.g.
or initramfs, dracut, … Then type exit to finish
と出るので「OK」を選択。
プロンプトでinitrdの再構築を行う。
sh-4.1# cd /boot/
sh-4.1# ls -lhtr vmlinuz*
一番下のバージョンのimgでinitrdを再生成。
今回はこんな感じだった。
sh-4.1# mkinitrd -f -v initramfs-2.6.32-573.12.1.el6.x86_64.img 2.6.32-573.12.1.el6.x86_64
再構築が終わったら
sh-4.1# exit
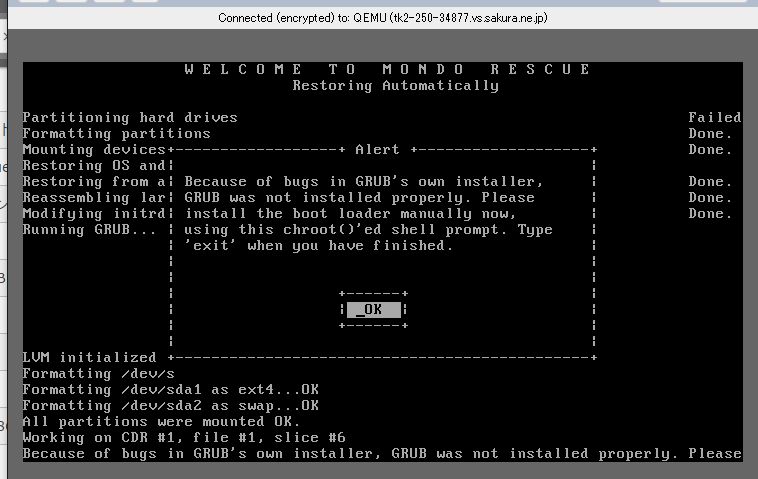
すこし待つと、
Because of bugs in GRUB’s own installer,
GRUB was not installed properly. Please install the boot loadermanually now,
using this chroot()’ed shell prompt. Type ‘exit’ when you have finished.
と出るので「OK」を選択。
grubのインストールを試みる。
sh-4.1# grub-install /dev/sda
/dev/sda does not have any corresponding BIOS drive./boo
とエラーが出てしまったのでいろいろ捜索。
「/etc/mtab」に「vda」の記述が残っていることを発見したのでこれを修正する。
sh-4.1# vi /etc/mtab
それと「/boot/grub/device.map」に「vda」の記述が残っていることを発見したのでこれを修正する。
sh-4.1# vi /boot/grub/device.map
再度「grub-install」を実行。
sh-4.1# grub-install /dev/sda
・・・
(hd0) /dev/sda
このように最後に表示されればOKっぽい。
プロンプトを抜ける。
sh-4.1# exit
最後に
Mondo has restored your system.
・・・
と表示されるので「OK」を選択。
プロンプトを抜ける。
sh-4.1# exit
その後何も起きないので、VPSの管理画面から
「強制再起動」を行う。
ログインプロンプトが表示されればOK。
今回は同じサーバにリストアしたので、ネットワーク関係の
再設定はいらないはず。
違うVPSにリストアする場合はUUID関係とかも調整しないと
いけないのかもしれない。。
今回同じサーバにも関わらず「Automatically」で全部できなかったのは
バックアップの時にカーネル検出を失敗していたのかもしれないと↓の
ブログを拝見して思いました。
さくらのVPSでOSイメージを作ってまるごとコピー
あと、VirtIOでも大丈夫って書いてある記事もあったのだけど
なんでできなかったのかは不明。
とりあえず、有事の際にローカルの仮想環境や元のVPSで
リストアできるところまでは検証できた。